Если вы опытный футболист, который читает защитные схемы так же легко, как вывески на улице, или кинозвезда, чье имя само по себе может сделать кассу фильму, или биржевой маклер, знающий свое дело лучше Уоррена Баффетта, то наши поздравления: вас будут ценить так же, как специалиста по обработке данных или инженера по машинному обучению с докторской степенью Стэнфорда, Массачусетского технологического или Университета Карнеги-Меллон. Каждая компания Кремниевой долины – и все больше компаний в других регионах – стремится заполучить таких специалистов, участвуя в некоем подобии игры на захват флага, только в области кадровой политики. Компании все больше понимают, что их конкурентоспособность зависит от использования машинного обучения и , и количество вакансий для специалистов в этих областях значительно превышает то, что нужно , и другим супердержавам.
Но что если бы вы смогли получить преимущества использования ИИ без необходимости нанимать этих редких и дорогостоящих специалистов? Что если этот порог входа можно понизить с помощью умного ПО? Можно ли использовать глубинное обучение с менее разнообразным набором кадров?
Стартап под названием Bonsai и целая группа похожих компаний отвечают на этот вопрос «да». Приготовьтесь к демократизации искусственного интеллекта. Когда-нибудь это движение может объединить под своими знаменами миллионы, если не миллиарды людей.
На Конференции разработчиков искусственного интеллекта О’Райли в Нью-Йорке генеральный директор Bonsai Марк Хаммонд провел презентацию своей компании. (Также он объявил о раунде инвестиций на сумму в $6 млн – не такие уж большие деньги, учитывая тот факт, что в этом году размер венчурных инвестиций в сферу ИИ уже 1,5 млрд.) Презентация включала повторение одного из самых известных достижений элитных разработчиков глубинного обучения: прохождение алгоритмом DeepMind старых игр для компьютеров Atari в реальном времени. В частности, игра под названием Breakout («Теннис»), в которой платформа отбивает квадратный «мяч», разбивающий мерцающие блоки. (Игра, выпущенная в 1976 году, была прорывом для своего времени – над ней работал сам )
37 строчек кода – вся структура нейросети, которая обучается через классическую игру Atari. Источник: Bonsai
Вариант, предложенный DeepMind, был создан лучшими в мире специалистами по ИИ, которые обучали нейросеть основам игр от Atari, и результат их работы был достоин научных публикаций мирового класса. Версия от Bonsai является упрощением. Все начинается с системы развития, которая загружена в облако. Всего один программист, пусть даже тот, кто вообще не обучался основам ИИ, может в общих чертах описать игру, а система сама выберет подходящий алгоритм обучения, чтобы задействовать нейросеть. (Бедным докторам наук из DeepMind приходилось писать эти алгоритмы самостоятельно). На этом этапе программисту нужно всего лишь за пару минут заложить основные принципы игры – например, «ловить мяч на платформу» - а затем Bonsai сама займется развитием нейросети и ее оптимизацией для получения наилучшего результата. А нейросеть на выходе уже сама будет играть в «Теннис».
Версия игры, написанная Bonsai, укладывается всего в 37 строчек кода. Но эта простота обманчива. Когда Хаммонд объясняет, что находится в основе алгоритма, он показывает рисунок с демонстрацией того, как его система строит нейросеть, способную соперничать с одним из лучших творений Google. Самому программисту даже не пришлось вникать в тонкости машинного обучения. Смотри, мам, я могу без рук докторской степени!

Так играет в «Теннис» нейросеть, обученная системой Bonsai. Источник: Bonsai
Впечатляющий трюк. «Обычно меня трудно удивить демонстрацией, - рассказывает Джордж Уильямс, научный сотрудник Курантовского института математики Нью-Йоркского университета. - Однако то, что показал мне Марк, было вполне реально и в то же время потрясающе. Он взял все достижения машинного интеллекта и создал инструменты, которые позволят разработать новое поколение систем ИИ».
Пока неясно, останется ли Bonsai лидером этого движения. Но Уильямс прав. Следующим шагом в неотвратимом появлении все более умных компьютеров будет разработка инструментов машинного обучения для (относительных) чайников.
Bonsai была рождена на пляже. Хаммонд, бывший инженер и евангелист разработки ПО, уже какое-то время раздумывал над возможностями искусственного интеллекта. После ухода из Microsoft в 2004 году он стал заниматься нейробиологией в Йеле, затем в 2010 году недолгое время проработал в Numenta – стартапе по разработке ИИ, которым владел Джефф Хокинс (сооснователь компании Palm, производителя КПК). Затем Хаммонд открыл еще одну компанию в совсем другой сфере, которую он затем продал.
Тогда, в 2012 году, Хаммонд приехал в Южную Калифорнию навестить друзей. Его маленький сын устал, и все пошли обратно к машине. Пока жена Хаммонда болтала с друзьями, а сын засыпал у него на руках, он провел мысленный эксперимент. В основе этого эксперимента лежал популярные мем из мира ИИ – концепция «мастер-алгоритма». Профессор Вашингтонского университета Педро Домингес в одноименной книге написал, что этот еще не созданный алгоритм мог бы стать панацеей для всех проблем отрасли. По идее, когда этот алгоритм все-таки изобретут, с его помощью можно будет методически внедрять системы ИИ куда угодно.
Хаммонд заключил, что нужно создать систему, которая позволит даже самому заурядному разработчику использовать инструменты ИИ Но Хаммонд видел один изъян в этой идее. «Допустим, мы нашли этот мастер-алгоритм, – говорил он себе, пока 18-месячный сын дремал у него на руках – кто станет внедрять его в бесчисленном множестве возможных сценариев?» На данный момент использовать такие инструменты под силу только настоящим адептам машинного обучения. Возможностей использования ИИ будет слишком много для ограниченного числа этих людей. Так он пришел к заключению, что нужно создать систему, которая снизит порог входа и позволит даже самому заурядному разработчику использовать эти инструменты. Такой системе не нужны будут инженеры крайне узкой специализации для обучения нейросетей. Программисты смогут сами обучать их для получения желаемого результата.
Пока Хаммонд обдумывал свои идеи, он провел аналогии с историей программирования. Изначально операторам компьютеров приходилось кропотливо писать код, который обеспечивал работу оборудования. Затем программисты взяли на вооружение набор стандартных инструкций, который был назван языком ассемблера и ускорил процесс – но вам все еще нужно было иметь очень высокий уровень подготовки, чтобы довести дело до ума. Прорыв случился, когда инженеры создали компилятор – программу, которая преобразовывала код на более удобных, так называемых языках «высокого уровня» (от самых первых BASIC и LISP до нынешних Python и C), в код на языке ассемблера. Только после этого создание мощных приложений стало доступно даже профессионалам относительно низкого уровня. Хаммонд считает, что сейчас, благодаря инструментам вроде TensorFlow от Google, системы ИИ вышли на уровень языка ассемблера, то есть инженерам уже становится легче создавать нейросети, но это все равно остается доступным тем, кто действительно понимает принцип их работы. Хаммонд хотел создать аналог компилятора, чтобы упростить все еще больше.
Этой идеей он поделился с Кином Брауном, бывшим коллегой из Microsoft, который недавно продал свой игровой стартап китайской интернет-компании. Идея ему понравилась, так как в то время он как раз пробовал заниматься машинным обучением, используя доступные на тот момент инструменты. «Вообще я человек неглупый, - говорит Браун - я приехал в Китай и выучил их язык, работал программистом в Microsoft, но даже для меня это было слишком». Он согласился стать сооснователем Bonsai. (Название было выбрано, потому что в этом японском искусстве достигается идеальный баланс между естественным и искусственным. Еще одно преимущество появилось, когда владельцы интернет-домена разрешили молодой компании зарегистрировать свой сайт по адресу bons.ai .)
Bonsai – не единственная компания, работающая над решением проблемы нехватки квалифицированных специалистов по ИИ. Некоторые из более крупных компаний поняли необходимость обучения собственных кадров и обучения обычных программистов в мастеров по нейросетям: в Google создали целую серию внутренних программ, а Apple стала обращать внимание на навыки и личные качества программистов, которые помогли бы им быстрее освоить нужные умения. Как уже говорилось выше, Google также выпустила в широкий доступ программу TensorFlow, благодаря которой ее инженерам проще создавать нейросети. Уже доступны и другие наборы инструментов для создания ИИ, и, без сомнения, таких инструментов будет становиться только больше.
«Мы открываем новые возможности для тех, кто не является ученым или программистом» В то же время другие стартапы тоже трудятся во имя демократизации ИИ. Компания Bottlenose решает проблему нехватки ученых, но для другой целевой аудитории: если Bonsai делает свой продукт в первую очередь для разработчиков ПО, Bottlenose планирует облегчить жизнь бизнес-аналитикам. Однако мотивы те же самые. «Мы открываем новые возможности для тех, кто не является ученым или программистом», - говорит генеральный директор компании Нова Спивак. Некоторые стартапы собираются затронуть еще больше пользователей: презентация компании Clarifai на конференции О’Райли называлась «Как сделать так, чтобы каждый человек на планете мог обучить и использовать ИИ».
Таким образом, хотя Bonsai, похоже, появилась в нужное время в нужном месте, сейчас индустрия ИИ настолько бурно развивается, что у стартапа Хаммонда могут возникнуть трудности с привлечением к себе внимания. Адам Чейер, специалист по ИИ, который участвовал в создании и сейчас занимает пост главного инженера , уже видел продукт Bonsai и остался очень впечатлен. Но он отмечает, что, хотя Bonsai делает ИИ доступным даже новичкам, людям все равно придется совершать умственные усилия, чтобы разобраться в их языке программирования и общем устройстве системы. «Когда новый продукт выпускает большая компания вроде Google, люди со всех ног бросаются его пробовать. Но если такой же продукт делает стартап, привлечь к нему людей намного сложнее. Хватит ли у них сил, чтобы задействовать достаточное количество пользователей и сделать свой инструмент популярным? Получится ли все у Bonsai или нет – сложно сказать прямо сейчас».
Компания создала систему из нескольких компонентов, среди которых Brain, облачная система для создания нейросетей, язык написания скриптов под названием Inkling и Mastermind, «интегрированная среда для разработки», которая предоставляет программистам все необходимые инструменты в одном месте. («Приложение для создания приложений», - объясняет Браун). Система Bonsai доступна для бета-тестирования.

Марк Хаммонд в главном офисе Bonsai в центре Беркли. Фото: Backchannel
Как объясняет Хаммонд, построение нейросети с помощью Bonsai в нескольких ключевых моментах отличается от того, как это делают профессионалы. На сегодня вам приходится решать, какие инструменты лучше всего подходят для решения проблемы, а для этого решения требуются знания и опыт. По словам Хаммонда, Bonsai делает это за вас. Вам остается только изложить основы того, чему вы хотите научить систему.
Так что пока опытные инженеры систем ИИ «тренируют» сеть, сравнивая информацию на выходе с желаемым результатом (например, показывая сети фотографии собак и поощряя ее при выводе подходящих характеристик), Bonsai позволяет вам «научить» систему, просто разбив весь процесс на основные принципы. Если продолжить пример с собаками, то вы могли бы упомянуть такие вещи, как четыре лапы, морда и язык, свисающий изо рта. Вы даете только необходимую базу, а облачный «умный движок» Bonsai, в который входит и «мозг», доводит дело до конца.
Такой подход дает косвенный положительный эффект: ученые, обучившие традиционную нейросеть, часто понятия не имеют, как именно творится магия, потому что такие сети в основном перенастраивают себя сами, организуя все понятным только себе образом. В случае с Bonsai понять принципы мышления сети можно по тем правилам, которые заложил пользователь. «Программное обеспечение не должно быть черным ящиком», - говорит Хаммонд. К примеру, если вы создаете программу для беспилотного автомобиля, и он не остановился в нужный момент, вы должны иметь возможность вникнуть и понять, почему система приняла такое решение. Примерно так же Amazon объясняет , почему та или иная книга появилась у вас в рекомендациях.
Один большой вопрос к подходу Bonsai состоит в том, снизят ли все эти абстрактные вещи производительность и эффективность. Обычно именно это происходит при использовании компиляторов: программы, написанные с их помощью, работают не так быстро и эффективно, как те, что написаны на языке ассемблера и передаются напрямую в аппаратную часть. Кроме того, говорить, что система, которая сама выбирает инструмент для использования, делает это лучше тех профессоров, которым уже вроде как и не нужно заниматься построением нейросетей, было бы явным преувеличением.
«Я думаю, всегда приходится идти на компромисс, - говорит Лайла Третиков, специалист по ИИ, ранее работавшая главой фонда Wikimedia Foundation и консультировавшая Bonsai. - Результаты будут не совсем такими же, как если задействовать группу ученых. Но я не уверена, что важнее: качество или сама по себе возможность это сделать». Адам Чейер из Viv также предполагает, что код Bonsai может работать не так эффективно, как ПО, оптимизированное под конкретную задачу. «Но это все равно чертовски хороший код, и он позволяет вам не вдаваться в ненужные тонкости», - добавляет он. Чейер также говорит, что в его компании, где как раз работают столь ценные специалисты по ИИ, вряд ли будут пользоваться Bonsai - разве что для создания прототипа какой-либо из идей перед тем, как реализовать ее старым проверенным способом.
Bonsai помогает движению за появление доступа к ИИ у людей, не имеющих специальной подготовки Хаммонд, в свою очередь, заверяет, что проигрыш в качестве при использовании Bonsai совсем не велик. «Производительность со временем увеличивается, – говорит он – в это просто нужно поверить». Когда-нибудь в это можно будет не только поверить, но и проверить.
У Bonsai большие планы на следующие несколько месяцев. Совсем скоро компания объявит о начале сотрудничества с производителем компонентов Nvidia, и клиенты Bonsai смогут получить более качественные результаты при использовании оборудования этой марки. Также компания опубликует информацию о своем договоре с центром Siemens TTB, который последние несколько месяцев тестировал систему Bonsai в области автоматизации и контроля производства.
Bonsai пытается решить проблемы, которые не смогли решить даже самые могущественные компании. «Мы работаем над многими играми», - добавляет Хаммонд и объясняет, что игры решают ключевые проблемы, которые планируют разрешить в Bonsai. «Некоторые игры не поддаются даже DeepMind. Хотя они научили свой алгоритм играть во множество игр помимо «Тенниса», пока их система еще не способна играть в «Пакмена».
Но намного важнее то, как Bonsai помогает движению за появление доступа к ИИ у людей, не имеющих специальной подготовки. Со временем инструменты высокого уровня будут становиться все мощнее и, в конце концов, станут повсеместными. Дойдем ли мы до того момента, когда каждый человек сможет обучить и использовать искусственный интеллект? Скажем так: очень много денег поставлено именно на этот вариант развития событий.
Правильная постановка вопроса должна быть такой: как натренировать сою собственную нейросеть? Писать сеть самому не нужно, нужно взять какую-то из готовых реализаций, которых есть множество, предыдущие авторы давали ссылки. Но сама по себе эта реализация подобна компьютеру, в который не закачали никаких программ. Для того, чтобы сеть решала вашу задачу, ее нужно научить.
И тут возникает собственно самое важное, что вам для этого потребуется: ДАННЫЕ. Много примеров задач, которые будут подаваться на вход нейросети, и правильные ответы на эти задачи. Нейросеть будет на этом учиться самостоятельно давать эти правильные ответы.
И вот тут возникает куча деталей и нюансов, которые нужно знать и понимать, чтобы это все имело шанс дать приемлемый результат. Осветить их все здесь нереально, поэтому просто перечислю некоторые пункты. Во-первых, объем данных. Это очень важный момент. Крупные компании, деятельность которых связана с машинным обучением, обычно содержат специальные отделы и штат сотрудников, занимающихся только сбором и обработкой данных для обучения нейросетей. Нередко данные приходится покупать, и вся эта деятельность выливается в заметную статью расходов. Во-вторых, представление данных. Если каждый объект в вашей задаче представлен относительно небольшим числом числовых параметров, то есть шанс, что их можно прямо в таком сыром виде дать нейросети, и получить приемлемый результат на выходе. Но если объекты сложные (картинки, звук, объекты переменной размерности), то скорее всего придется потратить время и силы на выделение из них содержательных для решаемой задачи признаков. Одно только это может занять очень много времени и иметь гораздо более влияние на итоговый результат, чем даже вид и архитектура выбранной для использования нейросети.
Нередки случаи, когда реальные данные оказываются слишком сырыми и непригодными для использования без предварительной обработки: содержат пропуски, шумы, противоречия и ошибки.
Данные должны быть собраны тоже не абы как, а грамотно и продуманно. Иначе обученная сеть может вести себя странно и даже решать совсем не ту задачу, которую предполагал автор.
Также нужно представлять себе, как грамотно организовать процесс обучения, чтобы сеть не оказалась переученной. Сложность сети нужно выбирать исходя из размерности данных и их количества. Часть данных нужно отложить для теста и при обучении не использовать, чтобы оценить реальное качество работы. Иногда различным объектам из обучающего множества нужно приписать различный вес. Иногда эти веса полезно варьировать в процессе обучения. Иногда полезно начинать обучение на части данных, а по мере обучения добавлять оставшиеся данные. В общем, это можно сравнить с кулинарией: у каждой хозяйки свои приемы готовки даже одинаковых блюд.
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется
Нейросети сейчас в моде, и не зря. С их помощью можно, к примеру, распознавать предметы на картинках или, наоборот, рисовать ночные кошмары Сальвадора Дали. Благодаря удобным библиотекам простейшие нейросети создаются всего парой строк кода, не больше уйдет и на обращение к искусственному интеллекту IBM.
Теория
Биологи до сих пор не знают, как именно работает мозг, но принцип действия отдельных элементов нервной системы неплохо изучен. Она состоит из нейронов - специализированных клеток, которые обмениваются между собой электрохимическими сигналами. У каждого нейрона имеется множество дендритов и один аксон. Дендриты можно сравнить со входами, через которые в нейрон поступают данные, аксон же служит его выходом. Соединения между дендритами и аксонами называют синапсами. Они не только передают сигналы, но и могут менять их амплитуду и частоту.
Преобразования, которые происходят на уровне отдельных нейронов, очень просты, однако даже совсем небольшие нейронные сети способны на многое. Все многообразие поведения червя Caenorhabditis elegans - движение, поиск пищи, различные реакции на внешние раздражители и многое другое - закодировано всего в трех сотнях нейронов. И ладно черви! Даже муравьям хватает 250 тысяч нейронов, а то, что они делают, машинам определенно не под силу.
Почти шестьдесят лет назад американский исследователь Фрэнк Розенблатт попытался создать компьютерную систему, устроенную по образу и подобию мозга, однако возможности его творения были крайне ограниченными. Интерес к нейросетям с тех пор вспыхивал неоднократно, однако раз за разом выяснялось, что вычислительной мощности не хватает на сколько-нибудь продвинутые нейросети. За последнее десятилетие в этом плане многое изменилось.
Электромеханический мозг с моторчиком

Машина Розенблатта называлась Mark I Perceptron. Она предназначалась для распознавания изображений - задачи, с которой компьютеры до сих пор справляются так себе. Mark I был снабжен подобием сетчатки глаза: квадратной матрицей из 400 фотоэлементов, двадцать по вертикали и двадцать по горизонтали. Фотоэлементы в случайном порядке подключались к электронным моделям нейронов, а они, в свою очередь, к восьми выходам. В качестве синапсов, соединяющих электронные нейроны, фотоэлементы и выходы, Розенблатт использовал потенциометры. При обучении перцептрона 512 шаговых двигателей автоматически вращали ручки потенциометров, регулируя напряжение на нейронах в зависимости от точности результата на выходе.
Вот в двух словах, как работает нейросеть. Искусственный нейрон, как и настоящий, имеет несколько входов и один выход. У каждого входа есть весовой коэффициент. Меняя эти коэффициенты, мы можем обучать нейронную сеть. Зависимость сигнала на выходе от сигналов на входе определяет так называемая функция активации.
В перцептроне Розенблатта функция активации складывала вес всех входов, на которые поступила логическая единица, а затем сравнивала результат с пороговым значением. Ее минус заключался в том, что незначительное изменение одного из весовых коэффициентов при таком подходе способно оказать несоразмерно большое влияние на результат. Это затрудняет обучение.
В современных нейронных сетях обычно используют нелинейные функции активации, например сигмоиду. К тому же у старых нейросетей было слишком мало слоев. Сейчас между входом и выходом обычно располагают один или несколько скрытых слоев нейронов. Именно там происходит все самое интересное.

Чтобы было проще понять, о чем идет речь, посмотри на эту схему. Это нейронная сеть прямого распространения с одним скрытым слоем. Каждый кружок соответствует нейрону. Слева находятся нейроны входного слоя. Справа - нейрон выходного слоя. В середине располагается скрытый слой с четырьмя нейронами. Выходы всех нейронов входного слоя подключены к каждому нейрону первого скрытого слоя. В свою очередь, входы нейрона выходного слоя связаны со всеми выходами нейронов скрытого слоя.
Не все нейронные сети устроены именно так. Например, существуют (хотя и менее распространены) сети, у которых сигнал с нейронов подается не только на следующий слой, как у сети прямого распространения с нашей схемы, но и в обратном направлении. Такие сети называются рекуррентными. Полностью соединенные слои - это тоже лишь один из вариантов, и одной из альтернатив мы даже коснемся.
Практика
Итак, давай попробуем построить простейшую нейронную сеть своими руками и разберемся в ее работе по ходу дела. Мы будем использовать Python с библиотекой Numpy (можно было бы обойтись и без Numpy, но с Numpy линейная алгебра отнимет меньше сил). Рассматриваемый пример основан на коде Эндрю Траска.
Нам понадобятся функции для вычисления сигмоиды и ее производной:
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «сайт», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score!
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор функции активации для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как обучение нейронной сети.
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых обратным распространением
Последовательный график ниже иллюстрирует процесс:

Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется градиентным спуском .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
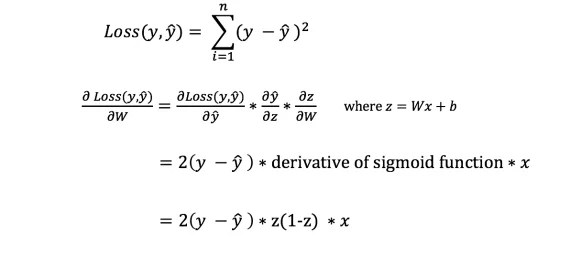
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.

Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!